반응형
[머신러닝] KNN (K-최근접 이웃, K-Nearest Neighbors) 훈련데이터와 테스트 데이터로 나누기
1) 데이터 살피기
# 도미, 방어 데이터
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]# 각 생선의 길이와 무게를 하나의 리스트로 담은 2차원 리스트
fish_data = [[l,w] for l,w in zip(fish_length,fish_weight)]
fish_target = [1]*35 + [0]*14
fish_data[[25.4, 242.0],
[26.3, 290.0],
[26.5, 340.0],
[29.0, 363.0],
[29.0, 430.0],
[29.7, 450.0],
[29.7, 500.0],
[30.0, 390.0],
# 총 39개의 데이터# 사이킷런의 kneighborsClassifier 클래스 임포트
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()print(fish_data[4])
print(fish_data[0:5]) # 마지막 인덱스의 원소는 포함되지 않음
print(fish_data[:5])
print(fish_data[44:]) # 마지막 인덱스 안쓰면 맨 마지막까지 뽑음[29.0, 430.0]
[[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0]]
[[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0]]
[[12.2, 12.2], [12.4, 13.4], [13.0, 12.2], [14.3, 19.7], [15.0, 19.9]]
2) 훈련데이터 테스트데이터 나누기
#훈련
train_input = fish_data[:35]
train_target = fish_target[:35]
# 테스트
test_input = fish_data[35:]
test_target = fish_target[35:]kn = kn.fit(train_input,train_target)
kn.score(test_input,test_target)
이렇게 하면 정확도 0임. 왜냐하면 데이터가 0부터 34에는 도미, 데이터가 35부터 마지막까지 방어가 있기 때문. 데이터가 몰려있어서 훈련데이터로 훈련하면 전부다 도미로 훈련됨. 샘플링 편향이 있음. 상식적으로 훈련하는 데이터와 테스트하는 데이터에는 도미와 방어가 골고루 섞여 있어야 한다.
3) NUMPY
import numpy as np
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)print(input_arr)[[ 25.4 242. ]
[ 26.3 290. ]
[ 26.5 340. ]
[ 29. 363. ]
[ 29. 430. ]
[ 29.7 450. ]
[ 29.7 500. ]
[ 30. 390. ]
# 39개의 데이터가 나옴print(target_arr)[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0]
# 39개의 데이터가 나옴
np.random.seed(42)
index = np.arange(49)
np.random.shuffle(index)
print(index)#shuffle 전 index
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
48]
#shuffle 후 index
[13 45 47 44 17 27 26 25 31 19 12 4 34 8 3 6 40 41 46 15 9 16 24 33
30 0 43 32 5 29 11 36 1 21 2 37 35 23 39 10 22 18 48 20 7 42 14 28
38]# numpy는 슬라이싱 외에 배열인덱싱 기능 제공
print(input_arr[[1,3]])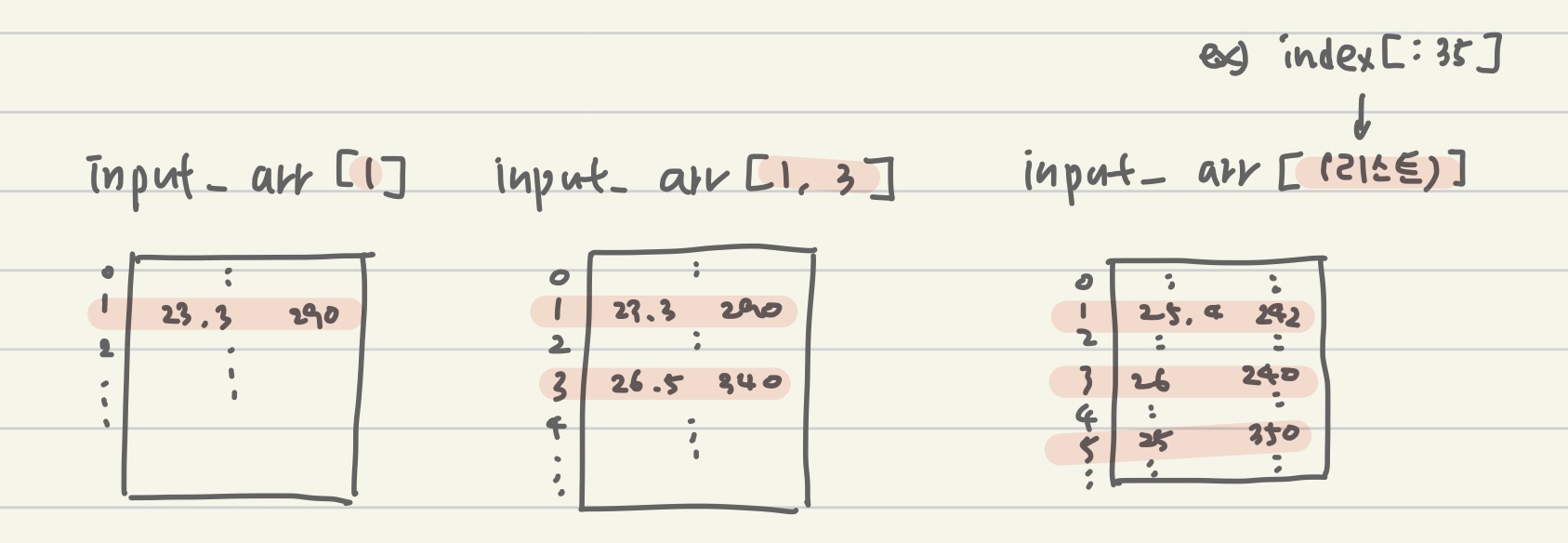
4) 훈련 데이터와 테스트 데이터로 나누기
train_input = input_arr[index[:35]]
train_target = target_arr[index[:35]]
test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]# 잘 섞였는지 산점도로 그리기
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0],train_input[:,1]) # length, weight
plt.scatter(test_input[:,0],test_input[:,1]) # length, weight
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
5) 두번째 프로그래밍 k-최근접 이웃 모델
kn = kn.fit(train_input,train_target)
kn.score(test_input,test_target)1.0정확도 1 (100%) 가 나왔음
kn.predict(test_input)array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])test_targetarray([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])
요약
모델을 사용할때 훈련 데이터로 모델을 평가하는 것은 답안지 보여주고 시험보는 것과 같음. 훈련 데이터, 테스트 데이터를 아무렇게나 나누는 것이 아니고 도미와 방어가 골고루 섞일 수 있도록 해야함. 여기서는 shuffle()을 이용하여 배열의 인덱스를 섞었음.
반응형
'python' 카테고리의 다른 글
| [시계열 분석] 날짜, 시간 자료형, 도구 - datetime, 문자열변환, pandas 이용 (0) | 2022.04.21 |
|---|---|
| [머신러닝] KNN 회귀 (K-최근접 이웃 회귀) - 결정계수, 과대적합, 과소적합 문제 해결 (0) | 2022.04.11 |
| [머신러닝] 데이터 전처리 K-최근접 이웃 KNN (표준점수로 특성의 스케일 변환) (0) | 2022.04.08 |
| [머신러닝] 첫번째 머신러닝 프로그램 - KNN(k-최근접 이웃) 알고리즘 도미방어 구분하기 (0) | 2022.04.04 |
| python 공부 시작 (0) | 2022.02.09 |



